#json variable
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was created by web developers David Karp and Marco Arment.
Text
hmm today I will implement minecraft resource locations in rust <- clueless
#minecraft#rustlang#programming#i love serializing i love json files i love regex i love cloning a variable just to check the length
3 notes
·
View notes
Text
“I’m the greatest programmer ever” to “stupidest coding bug known to man” pipeline
#dragon bahs#i’m about to be done with my current game design and development project#and along the journey i found new and creative ways to break things#for example!#famously if you multiply a movement vector by a variable whose value is set to 0 then you will not move. hope this helps#also been learning to work with json files to save specific game data#and there was a cool and epic bug caused by the loading system#which would multiply all the items in your inventory everytime you exit and reload the game#turns out when you don’t destroy unnecessary game objects it causes problems. hope this helps
1 note
·
View note
Text
Snapshot 25w02a
Mostly just summarizing this from the article on minecraft.net, but:
New pigs. There are now cold and warm pigs!
New "pink petals" style blocks, for leaves on the ground as well as a new "wildflower" yellow flower.
Leaf piles can be made from smelting leaves, and can be used as a fuel source.
All leaf blocks now generate particles under them.
Yes that includes, for some reason, spruce leaves. They all also share a texture, tinted differently based on biome tint, seemingly.
The new pigs babies are based on the parents, not the biome.
Lodestones have a new crafting recipe, using iron instead of netherite! This makes them much more obtainable.
New sounds for iron blocks.
Zombified Piglins nerfed for farms heavily, must be killed by players.
Farm animals can spawn in badlands!
Bubble columns more optimized.
The pale gardens are now larger, and can generate woodland mansions!
Creakings can be nametagged, making them persist during the day! Apparently, if they're stuck with a player, they will still despawn, as well as if they get too far away from their heart, but still a nice change. Nametagged creakings are still resistant to damage and such too.
Creaking Hearts now have a new texture during the day.
The creaking heart & eye blossoms now use fixed time, as opposed to being effected by the weather / dimension brightness.
These are all the changes that most players will be excited about, but I'm going to put the more technical stuff that I usually focus on in a readmore so I can get this out sooner!
THE PIGS ARE DATA-DRIVEN. YOU CAN ADD YOUR OWN PIGS.
Tamed animals can now be owned by other entities than players.
Text components now use SNBT instead of JSON. This might have some neat ramifications, but we'll see. Might make text components more powerful, like variable text in books.
Fill / Clone / Setblock commands can now surpress block updates, giving massive new options to builders who use commands.
New "weapon" item component, makes making weapons easier than before, + shield negating can be applied to any item now with this data change.
"potion_duration_scale" component, which heavily hints that we may finally be getting data-driven potions very soon. This is basically how the game would normally handle "extend this potion, make it shorter if its a splash potion, shorter even more if its a tipped arrow"
"tool" component, allows players to specify whether a tool should be able to break blocks in creative mode, like how swords cannot.
253 notes
·
View notes
Note
How did you get started creating the script project? I think it would be fun to try to do something similar for deltarune, but I'm not sure how feasible it would actually be
the age old tale is "i was writing isat fanfiction and really wanted to get some dialogue exactly right, so i combed through 100% playthroughts on youtube to find the right spot and jotted down what i needed in a document except it got so fucking annoying i contemplated just making a website for it and then i got my grubby mits on both rpgmaker mv and the isat data files and it was all joever"
if it's the actual PROCESS. well. it was a bit of a mess. the first thing i did was make the website itself, hammering out a general layout using the sadgrl layout builder over a whole weekend and an increasingly yelling filled call with my sibling who actually knows how websites work.
you can take a look at this post where i answered what to look out for more in-depth.
i've only played ch1&2 but honestly? deltarune seems feasible. i've seen people datamine sprites from it, at least, it seems like the engine is pretty well documented.
so yah i first figured out i COULD do it, then i made the website + website layout for it (if you know how, you should also hammer out your individual page layout at this point and not wait for other people to show up and do it for you).
then i just took a crack at making a page except my process was fucking horrid, i didn't actually have all the data files nor a proper way to read them (didn't have rpgmaker mv back then, i just looked at the .json files and tried my best, which is why some weird half completed pages were floating around in the site's early days, like the tutorial one from back when). I got tired of this pretty quick and very legally aquired rpgmaker (i actually own it on steam now and i never talked about piracy in isatcord and you can prove nothing and because this ISN'T isatcord i can make blatant euphemisms.)
and at that point i just went at it making whatever scrappy pages interested me. it was a sorta trial-by-fire thing where i got more familiar with rpgmaker and isat in specific as i went along, instead of putting in the effort to figure out how shit works first, because i am just a very learn by doing kinda guy. and that's how it all went along till the legendary hero Gold showed up and taught me github and made everything better and prettier (before this i was pushing every minor change directly to neocities which was especially funny when i was tinkering w the layout so the site just updated twenty bajillion times that one weekend)
for deltarune you'd probably also be pretty chill splitting things by area, and maybe subdividing area stuff into normal/weird route as is the room pages with normal/act5 or something. the battle stuff looks interesting to do with all the act options.
so yeah refer to the linked post for general tips but again for deltarune you do probably have a good shot? just the general stuff, decide how you wanna host it early, make a test page to check out what a page should look like and how to format it, and everything else (like How The Hell Do I Portray Conditionals: the story of how the <details> tag saved us all), but the real obscure stuff is only gonna sneak up on ya when you're already many many pages deep and trying to figure out where one specific variable is increased because the rpgmaker search function SUCKS SO BAD. s192 my fucking nemesis.
best of luck 👍
i'll prolly stop answering questions about this stuff at some point unless someone is asking for smth specific (like how to connect ur github repo to ur neocities or smth) bcuz i feel like i've said all that can be said at this point on the topic. go forth wiki warriors
16 notes
·
View notes
Note
hi just dropped by to say YAY ANOTHER GODOT DEV !! shoutout godot ya i loved the game. actually i'm curious what method of saving did you use for the game?
GODOT NUMBER ONE WOKE ENGINE LETS GOOOOO
I put all important variables that tell the game where is the player narrative-wise into a neat lil dictionary. Then put that in a lovely JSON that gets exported and saved in a secret part of the computer >:3
#yes godot got called a 'woke engine' which is incredibly funny to me#this argentinian robot is WOKE
22 notes
·
View notes
Text
MortuuM: a Jcink board responsive skin

MortuuM is a multi-sale skin optimised for Google Chrome, Safari and Firefox.
LIVE PREVIEW ✱ KO-FI LINK
Basic features: → Full responsiveness for different screen resolutions, including mobile screens; → Fully customised Jcink HTML Templates (forum rows, topic rows, post rows, main profile, members list etc.); → Sidebar containing basic navigation sections; → Light/dark mode toggle; → Font-size toggle; → CSS variables for fonts, group colours (currently up to 6), background images; → Main profile includes a premade attributes and a virtues system. It also includes FizzyElf’s automatic thread tracker; → Guidebook webpage, including text styles so you can mix and match for your own templates; → Basic templates (announcements, face claim, 3 thread templates); → Full installation guide in PDF.
Before purchasing, please review my policies. You can also contact me via Discord (deathspells) if you happen to stumble on any issues.
After purchasing, you’ll get: the full XML to be uploaded to Jcink’s Admin CP; a JSON file containing the profile fields; an installation guide (PDF); policies file (PDF); text files containing some additional coding for the skin (i.e. basic templates).
14 notes
·
View notes
Text


ATLAS OBSCURA (60$)
ATLAS OBSCURA is a fully flex skin optimized for Chrome but has been adjusted for compatibility across Firefox and Safari. A low contrast, dark background is recommended. A live preview can be requested at any time through my support discord. PURCHASE HERE: https://ko-fi[DOT]com/s/740013f3a4 WEBPAGES HERE: https://ko-fi[DOT]com/s/07654e42a0 TEMPLATES: https://ko-fi[DOT]com/s/020489ee5a
Includes:
light/dark toggle sidebar that auto transitions to a module for mobile custom forums, topics, memberlist, posts (optional larger post avatar with sticky) tabbed, popup application profile member group colors set up across the skin css variables set up for images, fonts, and colors for ease of editing guest to member links on login for easy navigation various indicators for messages/alerts customized tooltips tabbed header basic post template with all basic styles (bold, italics, h1 through h7, blockquote, hr, lists, etc)
Files:
full xml file html templates xml file easy to import field set json file general installation guide pdf skin specific instructions with member group prefix/suffix codes and user fields
Policies:
credit must remain intact and unchanged you may not claim my codes as your own at any point, nor may they be used as a base for other projects I offer unlimited support for bugs present at purchase
Please review the rest of my my policies prior to making any purchases: koncodes[DOT]tumblr.com/policies For questions or a live preview, you can contact me through ko-fi or my support discord: discord[DOT]gg/MXD5nDgDzq
153 notes
·
View notes
Text
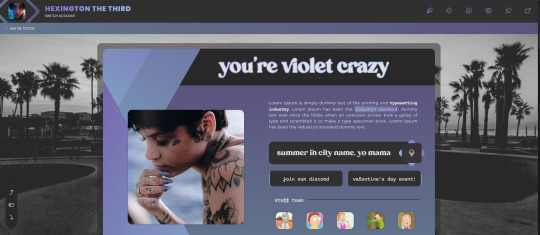
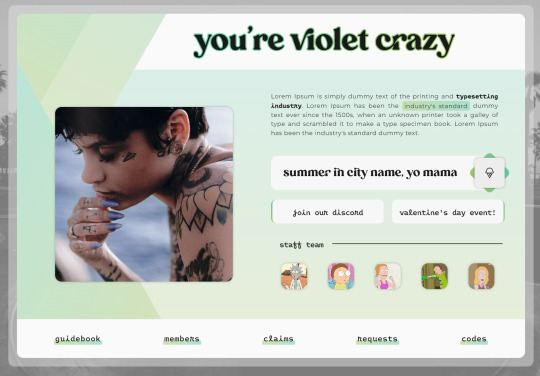
VIOLET CRAZY Jcink Skin - $60 CAD
VIOLET CRAZY is a fully responsive, mobile-friendly Jcink skin. I��ve made it as user-friendly as possible with easy-to-edit variables and cues within the HTML which are also in the installation guide. Template Set #1 and Freestyle Profile Templates are fully functional with this skin.
Please read my terms of service before purchasing: https://hexxincodes.tumblr.com/post/721896465243537408/terms-conditions Purchase on my kofi: https://ko-fi.com/s/fe74d1a98b
DETAILS -
All colors, fonts, and images set as variables for easy editing
Dark/light toggle
Full HTML templates
Isotope member list
Guidebook with 6 tabs set
Skin changes colors according to member group (10 set up)
Profile app with room for unlimited fields
Automatic tracker in profiles
Forums change accents w/ last poster
Full installation guide
UPON PURCHASE -
Full xml file
HTML templates xml file
Profile fields json
Installation guide pdf
Guidebook txt file
CREDITS - Isotope memberlist script is by Essi, the dark/light toggle script was created by Yuno, #CODE script is by Nicole/Thunderstruck, icons are from Phosphor Icons, automatic tracker by FizzyElf.






40 notes
·
View notes
Text
Interloper Devlog #1 - April 2025
I am BACK!
My move was successful and my computer remained unharmed so i was able to get back to work on the game!
This month I spent working on various things but mostly systems stuff.
Save and load
================
I want to start with the saving and loading first since its the simplest.
Both Saving and Loading are separated into their own scripts that can be called whenever I need (such as save points)

Here is the code for Saving! I'll explain what each part does since its so short.
Set the "currentSaveFile" variable to open a specific file when called. In this case "Save.sav"
Set the "currentSaveJson" variable to a different variable "global.currentSave" that has been converted into JSON text.
Open the "Save.sav" file by referencing "currentSaveFile" then save the JSON text to the file by referencing "currentSaveJson"
Close the file.
Then do that again for saving options.
Now loading is basically the same, just read the JSON text then convert it back to a variable.
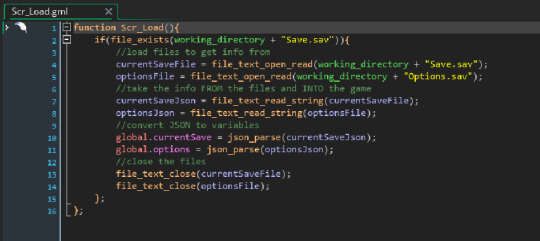
I'm not going to bother with a step by step here given the similar nature, something of note however is Line 2. Line 2 checks to make sure the file exists before attempting to load it, otherwise the game would crash if the file didn't exist.
Menu stuff
=============
Now its time to get into the goooood stuff, MENUS!
I looooved working on these so I'm quite excited to explain what I've done. Now most of what I've done is more systems stuff.
The menus are fairly fragmented across a few different objects and scripts so I'll have to be a bit more vague about the code.

So this is a menu, this is all the code needed to create one. If you wanted to create a menu for really anything this is what you'd type. This array contains 4 more arrays, with the following format.
[X,Y,Color,Text or Sprite],
Now there is more going on under the hood here, this alone wouldn't do anything. I have a fairly simple script that will auto draw each button by repeating multiple times per frame, the script will extract the length of the array and use the length as the repeat number. Each time it finishes drawing a button it'll go to the next button till its done all of them.

This code creates the background for the menu in a similar fashion. The format is slightly different but nearly the same.
[X1,Y1,X2,Y2,Color],
This will create a rectangle with the dimensions and color you want! The 'menuCMenu' rectangles create a black box with white outline!.
Now it should be noted that the position of the boxes in the array is VERY important. For the buttons the game uses the positions to decide which button to select next while navigating the menu, the background boxes use the order to decide which box is covered by another.
Putting both of these code snippets in actions gives us THIS!

You may have noticed (or maybe not) that the "Items" text is yellow in this screenshot while the code states that it should be white. During the rendering process of the buttons i do a check, if a certain button is selected then make the text color yellow instead of whatever it's supposed to be.
Dialogue
===========
While not a total rework i did end up changing how dialogue works.

Dialogue was always formatted in a similar way to the menus however I did end up changing it slightly. Before each line was just floating around in what was destined to become a huge variable. Now that soon to be huge variable contains smaller variables that contain the dialogue trees!. So let me explain this code snippet.
[Face,Emotion,Text,Next Dialogue Line],
Lets start with the Face. The face is as simple as it sounds, type in the sprite you want to appear in the dialogue box, i.e "Face_August"
Now sometimes you don't want a face to appear so in those cases you would input "Face_Steve". This face does exist and has a corresponding sprite, the only reason its used here to display no face is because it's kinda funny. The code that draws the dialogue will see the "Face_Steve" input and will draw a different box with no face.


The Emotion refers to the sprites index. So if Emotion was 1 then it would change "Face_August" to display frame 1 of the index.
Text is self explanatory, only thing of note is that you can type "\n" to start a new line.
Next Dialogue Line refers to the specific position in the array. Arrays start counting at 0 i.e 0, 1, 2. So referencing Line 1 would cause the second line to start. Now you'd need to stop the dialogue eventually so in that case you'd type in -1 since you can't go negative in array positions.
Misc Stuff
=============
I have a few more things to mention, very minor however.
I have an object whose only job is to create other objects such as "Obj_Controls"
The controls object basically checks for inputs and will update global variables every frame based on the input data.
I have an object that creates a camera, that's about it.
and finally i have an object for Dev testing which contains some code for drawing debug info and what not.
Final Notes
============
I don't have too many things to say here other than Thank You for taking time out of your day to read! Have a nice day :)
3 notes
·
View notes
Text

Anyway, new version of Menu Buttons of Stone is out. On Java Edition, all it really does is update the compatible game versions list and tweak a few textures, but on Bedrock Edition, it fixes an absolutely vital issue with current versions of VDX: Desktop UI.
Download Links:
Java Edition (Planet Minecraft)
Java Edition (Modrinth)
Bedrock Edition (Planet Minecraft)
Change Log:
Java Edition:
Pack now reads as compatible with game versions from 1.21.2 to 1.21.4.
Tweaked the bevels on the Recipe Book Button to more closely align with similar vanilla graphics.
Fixed some slightly miscolored pixels on the player report button.
Bedrock Edition:
Apparently, I just completely forgot to upload v1.2.1 and no-one told me (even though v1.2.0 is very noticeably broken), so this log will cover both v1.2.1 and v1.2.2.
v1.2.1
Bug Fixes and General Changes:
Pack is now ACTUALLY compatible with VDX: Desktop UI v3.0. Last MBoS version completely broke a number of container screens and I just didn't realize, but it's fixed now. (See A)
Subpacks now work using VDX: Desktop UI v3.0. (See B)
Various textures should no longer break when using MBoS over Thickly Be-Beveled Buttons. (See C)
The Accessibility Button icon now looks the same when using VDX: Desktop UI v3.0 as it does when using VDX: Legacy Desktop UI v1.2.9. (Added textures, JSON)
The Cross Button now uses the correct shade of white on its X when any subpack with white text is enabled (when using VDX: Desktop UI). (Added JSON, textures)
The outline of the hovered text field now matches the color of the active subpack's text when using VDX: Desktop UI or VDX: Legacy Desktop UI. (Added JSON, textures)
Changed pack icon to be more readable at a smaller scale and more accurately show off the effects of the pack.
Technical Changes:
A) When using VDX: Legacy Desktop UI v1.2.9 and below, the buttons on/for the Beacon Screen and Recipe Book are now changed via JSON instead of just including the texture sheets normally, since including the full texture sheets breaks newer versions of VDX: Desktop UI. (Added JSON, removed textures)
B) When using VDX: Desktop UI v3.0, hover textures for a number of various things are now set to a custom filepath (textures/cb_ui_sprites/) to get around filepath length limitations. To go along with this, the hover textures that were previously stored in the assets folder have been moved to the new one. (Added JSON, textures; moved textures)
C) Added nineslice information for all relevant Java Edition and VDX: 4JD UI textures, even if said information is unchanged from the textures' place of origin.
Removed all Java Edition textures not directly used by VDX: Desktop UI.
Removed blank space from texture sheets that had it, since Bedrock Edition doesn't care about its existence the way Java Edition does. (Edited textures)
Renamed subpack folder "blue_highlight_and_gold_outline" to "bh_and_go" because the filepath was still too long.
Renamed subpack folder "blue_highlight_and_yellow_outline" to "bh_and_yo" because this filepath was also still too long.
Added global variable ("$cb_is_stone_menu_buttons_v1.2.1": true).
Added global variables to each subpack to denote themselves, each following the formula "$cb_is_stone_menu_buttons_[SUBPACKNAME]", where [SUBPACKNAME] is the actual name of the subpack folder. For example, the subpack "blue_highlight_and_gold_outline" would use global variable ("$cb_is_stone_menu_buttons_bh_and_go": true).
Changed pack UUIDs.
v1.2.2
Fixed some slightly miscolored pixels on the textures for the Java Edition report button (VDX: Desktop UI).
Tweaked bevels on the Java Edition Recipe Book Button to more closely align with similar graphics in vanilla Java Edition.
Added textures for the 'warning' and 'error' exclamation marks on the VDX: Desktop UI World Select Screen for pixel size consistency. Not sure where CrisXolt put them, but they're in the files, so they must be used somewhere.
3 notes
·
View notes
Text
sigh...what annoys me now though is that the way i managed to get the items working means that every item in the game is going to have it's own constructor function, which seems really impractical for randomizing them...there is a very long switch case statement in my future that i think could have theoretically just been irandom_range(). But gamemaker kept saying that i was trying to read an undefined variable and pointing at the line that defined that variable and I never fixed that I just had to do it completely differently so it would shut up about it. I wish I could have had my json database file...People love json database files.............
4 notes
·
View notes
Note
hey i love your ISAT script site!! i'm wondering if you have the dialogue around the wish ritual anywhere? (the folding leaf and such - iirc there were two different books/essays in the game about it). and also wondering if you have like, a datamined text file anywhere? or is it all hand-transcribed?? thanks!!!
that was actually pretty highly requested dialogue (i know i've copy pasted it on isatcord TWICE lmao) so this ask gave me the impetus to whip it up!
here's a WIP page with it, for you!
(there's something really funny in reading fanfiction and knowing the writer cross-referenced my script, ngl.)
AS FOR THE FILES....
The game is actually entirely unencrypted, because insertdisc5 has mercy upon us. If you own the game on steam, you can open them up yourself, no problem, which is what i've been doing.
They're under Windows/Programs/steamapps/common/In Stars and Time/www/data
What you find here is precisely 217 map files, which contain the dialogue for all locations in the game. All dialogue NOT tied to a location (items, events that happen in multiple places, all dialogue in battles) are in Common Events, which is one huge fucker.
If you open them up, you will find a lot of intelligible code.
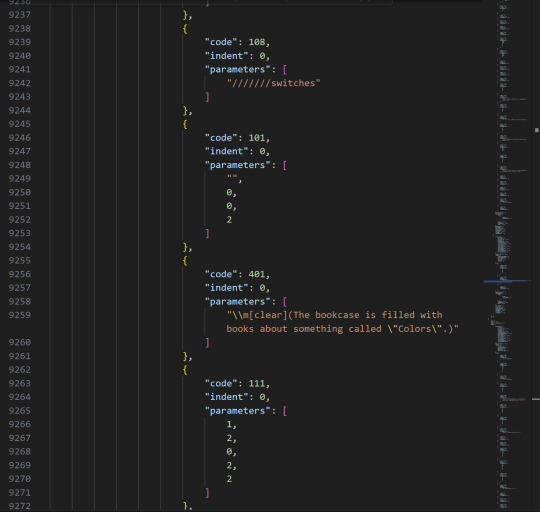
This is what it looks like in Visual Studio Code, which is the program I write my website in. I copy-paste all dialogue by hand, but thank god i do NOT need to transcribe anything. (I think Codacheetah did that for the og Loopchats document, which, dear god Coda, what are you doing).
Since actually knowing what goes where is super difficult with this, I also use RPGmaker MV (which i have obtained very legally) to make the text easier to parse!
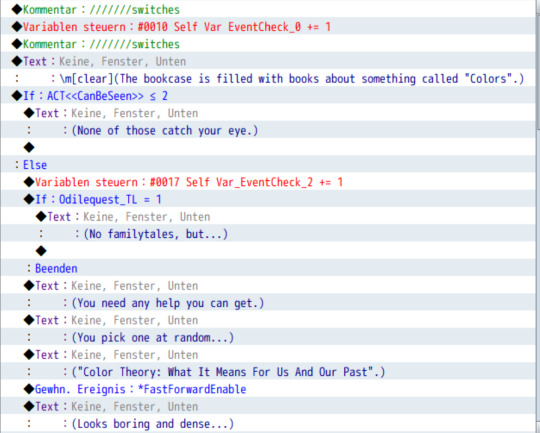
my program is set to german so this is some denglish. But already you can see the when and where of it, for some examples:
Self Var EventCheck is a variable that checks how often a specific event happens. These are subdivided by number on specific dialogue options within a single even tpage.
You also see other variables, like ACT <<CanBeSeen>> which just classifies which act this is in, so the line "(None of these catch your eye.)" only applies from act 2 onwards (which is redundant, since you can only access this bookshelf starting in act 2, but hey).
The upside of RPGmaker is that I can also just go to the room I need and then see which map its on, so I don't need to search through all 217 of those map files.
(When I started this project, I looked at and labelled all map files without using rpgmaker. This is stupid. Do not do this.)
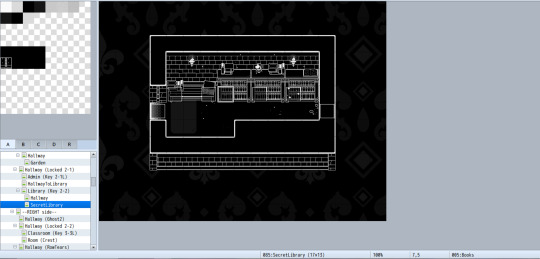
At the very bottom in that little bar, you can see that it says "085: SecretLibrary". 085 is the number of the map file, so the Secret Library Dialogue is in "Map085.json"
(I also list the file source of dialogue on the script site whenever I remember to, so that's what "Source: Map085" refers to.)
If you only want to search what a specific line is, or look up when a word is used, then just searching through the json files is more than enough.
I hope this was helpful!! Enjoy
9 notes
·
View notes
Text

Not sure why i didn't make a post for 1.0.1, but the Bedrock port of leaf4e's green hud is now on version 1.0.2! The things it fixes are mostly minor, with the exception of the new death screen, because it's Ore UI now.
(To clarify, leaf4e made the original pack, but I helped port it.) Anyway, links:
Java Edition 1.20.1
Java Edition 1.20.2+ (actually also compatible with older versions)
Bedrock Edition (the one with the update)
Changelog:
Bedrock Edition, pack version 1.0.2
General
Global variable "$cb_is_leaf4e_green_hud_v1.0.1" is now "$cb_is_leaf4e_green_hud_v1.0.2". (Edited JSON)
Default Subpack Only
New Death Screen is no longer broken. (Edited JSON)
The text and chevron on locked dropdowns should now be the correct color. (Edited, added JSON; added texture)
The chevrons on the buttons in the Dressing Room and Marketplace are now the correct color. (Added JSON)
UI texture "default_indent" should now be scaled properly when changing between this pack and vanilla. (Edited texture, JSON)
The outlines for the Layout Buttons in the Inventory are now the correct colors. (Edited, added JSON)
Started on WIP fix for the chevrons in the Chat Screen. It currently does not work. (Added texture, JSON)
#minecraft#minecraft java#minecraft bedrock#minecraft resource pack#green hud#(pretend i posted this to the correct blog lol)#id in alt
3 notes
·
View notes
Text
UNLOCKING THE POWER OF AI WITH EASYLIBPAL 2/2

EXPANDED COMPONENTS AND DETAILS OF EASYLIBPAL:
1. Easylibpal Class: The core component of the library, responsible for handling algorithm selection, model fitting, and prediction generation
2. Algorithm Selection and Support:
Supports classic AI algorithms such as Linear Regression, Logistic Regression, Support Vector Machine (SVM), Naive Bayes, and K-Nearest Neighbors (K-NN).
and
- Decision Trees
- Random Forest
- AdaBoost
- Gradient Boosting
3. Integration with Popular Libraries: Seamless integration with essential Python libraries like NumPy, Pandas, Matplotlib, and Scikit-learn for enhanced functionality.
4. Data Handling:
- DataLoader class for importing and preprocessing data from various formats (CSV, JSON, SQL databases).
- DataTransformer class for feature scaling, normalization, and encoding categorical variables.
- Includes functions for loading and preprocessing datasets to prepare them for training and testing.
- `FeatureSelector` class: Provides methods for feature selection and dimensionality reduction.
5. Model Evaluation:
- Evaluator class to assess model performance using metrics like accuracy, precision, recall, F1-score, and ROC-AUC.
- Methods for generating confusion matrices and classification reports.
6. Model Training: Contains methods for fitting the selected algorithm with the training data.
- `fit` method: Trains the selected algorithm on the provided training data.
7. Prediction Generation: Allows users to make predictions using the trained model on new data.
- `predict` method: Makes predictions using the trained model on new data.
- `predict_proba` method: Returns the predicted probabilities for classification tasks.
8. Model Evaluation:
- `Evaluator` class: Assesses model performance using various metrics (e.g., accuracy, precision, recall, F1-score, ROC-AUC).
- `cross_validate` method: Performs cross-validation to evaluate the model's performance.
- `confusion_matrix` method: Generates a confusion matrix for classification tasks.
- `classification_report` method: Provides a detailed classification report.
9. Hyperparameter Tuning:
- Tuner class that uses techniques likes Grid Search and Random Search for hyperparameter optimization.
10. Visualization:
- Integration with Matplotlib and Seaborn for generating plots to analyze model performance and data characteristics.
- Visualization support: Enables users to visualize data, model performance, and predictions using plotting functionalities.
- `Visualizer` class: Integrates with Matplotlib and Seaborn to generate plots for model performance analysis and data visualization.
- `plot_confusion_matrix` method: Visualizes the confusion matrix.
- `plot_roc_curve` method: Plots the Receiver Operating Characteristic (ROC) curve.
- `plot_feature_importance` method: Visualizes feature importance for applicable algorithms.
11. Utility Functions:
- Functions for saving and loading trained models.
- Logging functionalities to track the model training and prediction processes.
- `save_model` method: Saves the trained model to a file.
- `load_model` method: Loads a previously trained model from a file.
- `set_logger` method: Configures logging functionality for tracking model training and prediction processes.
12. User-Friendly Interface: Provides a simplified and intuitive interface for users to interact with and apply classic AI algorithms without extensive knowledge or configuration.
13.. Error Handling: Incorporates mechanisms to handle invalid inputs, errors during training, and other potential issues during algorithm usage.
- Custom exception classes for handling specific errors and providing informative error messages to users.
14. Documentation: Comprehensive documentation to guide users on how to use Easylibpal effectively and efficiently
- Comprehensive documentation explaining the usage and functionality of each component.
- Example scripts demonstrating how to use Easylibpal for various AI tasks and datasets.
15. Testing Suite:
- Unit tests for each component to ensure code reliability and maintainability.
- Integration tests to verify the smooth interaction between different components.
IMPLEMENTATION EXAMPLE WITH ADDITIONAL FEATURES:
Here is an example of how the expanded Easylibpal library could be structured and used:
```python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from easylibpal import Easylibpal, DataLoader, Evaluator, Tuner
# Example DataLoader
class DataLoader:
def load_data(self, filepath, file_type='csv'):
if file_type == 'csv':
return pd.read_csv(filepath)
else:
raise ValueError("Unsupported file type provided.")
# Example Evaluator
class Evaluator:
def evaluate(self, model, X_test, y_test):
predictions = model.predict(X_test)
accuracy = np.mean(predictions == y_test)
return {'accuracy': accuracy}
# Example usage of Easylibpal with DataLoader and Evaluator
if __name__ == "__main__":
# Load and prepare the data
data_loader = DataLoader()
data = data_loader.load_data('path/to/your/data.csv')
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Initialize Easylibpal with the desired algorithm
model = Easylibpal('Random Forest')
model.fit(X_train_scaled, y_train)
# Evaluate the model
evaluator = Evaluator()
results = evaluator.evaluate(model, X_test_scaled, y_test)
print(f"Model Accuracy: {results['accuracy']}")
# Optional: Use Tuner for hyperparameter optimization
tuner = Tuner(model, param_grid={'n_estimators': [100, 200], 'max_depth': [10, 20, 30]})
best_params = tuner.optimize(X_train_scaled, y_train)
print(f"Best Parameters: {best_params}")
```
This example demonstrates the structured approach to using Easylibpal with enhanced data handling, model evaluation, and optional hyperparameter tuning. The library empowers users to handle real-world datasets, apply various machine learning algorithms, and evaluate their performance with ease, making it an invaluable tool for developers and data scientists aiming to implement AI solutions efficiently.
Easylibpal is dedicated to making the latest AI technology accessible to everyone, regardless of their background or expertise. Our platform simplifies the process of selecting and implementing classic AI algorithms, enabling users across various industries to harness the power of artificial intelligence with ease. By democratizing access to AI, we aim to accelerate innovation and empower users to achieve their goals with confidence. Easylibpal's approach involves a democratization framework that reduces entry barriers, lowers the cost of building AI solutions, and speeds up the adoption of AI in both academic and business settings.
Below are examples showcasing how each main component of the Easylibpal library could be implemented and used in practice to provide a user-friendly interface for utilizing classic AI algorithms.
1. Core Components
Easylibpal Class Example:
```python
class Easylibpal:
def __init__(self, algorithm):
self.algorithm = algorithm
self.model = None
def fit(self, X, y):
# Simplified example: Instantiate and train a model based on the selected algorithm
if self.algorithm == 'Linear Regression':
from sklearn.linear_model import LinearRegression
self.model = LinearRegression()
elif self.algorithm == 'Random Forest':
from sklearn.ensemble import RandomForestClassifier
self.model = RandomForestClassifier()
self.model.fit(X, y)
def predict(self, X):
return self.model.predict(X)
```
2. Data Handling
DataLoader Class Example:
```python
class DataLoader:
def load_data(self, filepath, file_type='csv'):
if file_type == 'csv':
import pandas as pd
return pd.read_csv(filepath)
else:
raise ValueError("Unsupported file type provided.")
```
3. Model Evaluation
Evaluator Class Example:
```python
from sklearn.metrics import accuracy_score, classification_report
class Evaluator:
def evaluate(self, model, X_test, y_test):
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
report = classification_report(y_test, predictions)
return {'accuracy': accuracy, 'report': report}
```
4. Hyperparameter Tuning
Tuner Class Example:
```python
from sklearn.model_selection import GridSearchCV
class Tuner:
def __init__(self, model, param_grid):
self.model = model
self.param_grid = param_grid
def optimize(self, X, y):
grid_search = GridSearchCV(self.model, self.param_grid, cv=5)
grid_search.fit(X, y)
return grid_search.best_params_
```
5. Visualization
Visualizer Class Example:
```python
import matplotlib.pyplot as plt
class Visualizer:
def plot_confusion_matrix(self, cm, classes, normalize=False, title='Confusion matrix'):
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
```
6. Utility Functions
Save and Load Model Example:
```python
import joblib
def save_model(model, filename):
joblib.dump(model, filename)
def load_model(filename):
return joblib.load(filename)
```
7. Example Usage Script
Using Easylibpal in a Script:
```python
# Assuming Easylibpal and other classes have been imported
data_loader = DataLoader()
data = data_loader.load_data('data.csv')
X = data.drop('Target', axis=1)
y = data['Target']
model = Easylibpal('Random Forest')
model.fit(X, y)
evaluator = Evaluator()
results = evaluator.evaluate(model, X, y)
print("Accuracy:", results['accuracy'])
print("Report:", results['report'])
visualizer = Visualizer()
visualizer.plot_confusion_matrix(results['cm'], classes=['Class1', 'Class2'])
save_model(model, 'trained_model.pkl')
loaded_model = load_model('trained_model.pkl')
```
These examples illustrate the practical implementation and use of the Easylibpal library components, aiming to simplify the application of AI algorithms for users with varying levels of expertise in machine learning.
EASYLIBPAL IMPLEMENTATION:
Step 1: Define the Problem
First, we need to define the problem we want to solve. For this POC, let's assume we want to predict house prices based on various features like the number of bedrooms, square footage, and location.
Step 2: Choose an Appropriate Algorithm
Given our problem, a supervised learning algorithm like linear regression would be suitable. We'll use Scikit-learn, a popular library for machine learning in Python, to implement this algorithm.
Step 3: Prepare Your Data
We'll use Pandas to load and prepare our dataset. This involves cleaning the data, handling missing values, and splitting the dataset into training and testing sets.
Step 4: Implement the Algorithm
Now, we'll use Scikit-learn to implement the linear regression algorithm. We'll train the model on our training data and then test its performance on the testing data.
Step 5: Evaluate the Model
Finally, we'll evaluate the performance of our model using metrics like Mean Squared Error (MSE) and R-squared.
Python Code POC
```python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Load the dataset
data = pd.read_csv('house_prices.csv')
# Prepare the data
X = data'bedrooms', 'square_footage', 'location'
y = data['price']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create and train the model
model = LinearRegression()
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
# Evaluate the model
mse = mean_squared_error(y_test, predictions)
r2 = r2_score(y_test, predictions)
print(f'Mean Squared Error: {mse}')
print(f'R-squared: {r2}')
```
Below is an implementation, Easylibpal provides a simple interface to instantiate and utilize classic AI algorithms such as Linear Regression, Logistic Regression, SVM, Naive Bayes, and K-NN. Users can easily create an instance of Easylibpal with their desired algorithm, fit the model with training data, and make predictions, all with minimal code and hassle. This demonstrates the power of Easylibpal in simplifying the integration of AI algorithms for various tasks.
```python
# Import necessary libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
class Easylibpal:
def __init__(self, algorithm):
self.algorithm = algorithm
def fit(self, X, y):
if self.algorithm == 'Linear Regression':
self.model = LinearRegression()
elif self.algorithm == 'Logistic Regression':
self.model = LogisticRegression()
elif self.algorithm == 'SVM':
self.model = SVC()
elif self.algorithm == 'Naive Bayes':
self.model = GaussianNB()
elif self.algorithm == 'K-NN':
self.model = KNeighborsClassifier()
else:
raise ValueError("Invalid algorithm specified.")
self.model.fit(X, y)
def predict(self, X):
return self.model.predict(X)
# Example usage:
# Initialize Easylibpal with the desired algorithm
easy_algo = Easylibpal('Linear Regression')
# Generate some sample data
X = np.array([[1], [2], [3], [4]])
y = np.array([2, 4, 6, 8])
# Fit the model
easy_algo.fit(X, y)
# Make predictions
predictions = easy_algo.predict(X)
# Plot the results
plt.scatter(X, y)
plt.plot(X, predictions, color='red')
plt.title('Linear Regression with Easylibpal')
plt.xlabel('X')
plt.ylabel('y')
plt.show()
```
Easylibpal is an innovative Python library designed to simplify the integration and use of classic AI algorithms in a user-friendly manner. It aims to bridge the gap between the complexity of AI libraries and the ease of use, making it accessible for developers and data scientists alike. Easylibpal abstracts the underlying complexity of each algorithm, providing a unified interface that allows users to apply these algorithms with minimal configuration and understanding of the underlying mechanisms.
ENHANCED DATASET HANDLING
Easylibpal should be able to handle datasets more efficiently. This includes loading datasets from various sources (e.g., CSV files, databases), preprocessing data (e.g., normalization, handling missing values), and splitting data into training and testing sets.
```python
import os
from sklearn.model_selection import train_test_split
class Easylibpal:
# Existing code...
def load_dataset(self, filepath):
"""Loads a dataset from a CSV file."""
if not os.path.exists(filepath):
raise FileNotFoundError("Dataset file not found.")
return pd.read_csv(filepath)
def preprocess_data(self, dataset):
"""Preprocesses the dataset."""
# Implement data preprocessing steps here
return dataset
def split_data(self, X, y, test_size=0.2):
"""Splits the dataset into training and testing sets."""
return train_test_split(X, y, test_size=test_size)
```
Additional Algorithms
Easylibpal should support a wider range of algorithms. This includes decision trees, random forests, and gradient boosting machines.
```python
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
class Easylibpal:
# Existing code...
def fit(self, X, y):
# Existing code...
elif self.algorithm == 'Decision Tree':
self.model = DecisionTreeClassifier()
elif self.algorithm == 'Random Forest':
self.model = RandomForestClassifier()
elif self.algorithm == 'Gradient Boosting':
self.model = GradientBoostingClassifier()
# Add more algorithms as needed
```
User-Friendly Features
To make Easylibpal even more user-friendly, consider adding features like:
- Automatic hyperparameter tuning: Implementing a simple interface for hyperparameter tuning using GridSearchCV or RandomizedSearchCV.
- Model evaluation metrics: Providing easy access to common evaluation metrics like accuracy, precision, recall, and F1 score.
- Visualization tools: Adding methods for plotting model performance, confusion matrices, and feature importance.
```python
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import GridSearchCV
class Easylibpal:
# Existing code...
def evaluate_model(self, X_test, y_test):
"""Evaluates the model using accuracy and classification report."""
y_pred = self.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
def tune_hyperparameters(self, X, y, param_grid):
"""Tunes the model's hyperparameters using GridSearchCV."""
grid_search = GridSearchCV(self.model, param_grid, cv=5)
grid_search.fit(X, y)
self.model = grid_search.best_estimator_
```
Easylibpal leverages the power of Python and its rich ecosystem of AI and machine learning libraries, such as scikit-learn, to implement the classic algorithms. It provides a high-level API that abstracts the specifics of each algorithm, allowing users to focus on the problem at hand rather than the intricacies of the algorithm.
Python Code Snippets for Easylibpal
Below are Python code snippets demonstrating the use of Easylibpal with classic AI algorithms. Each snippet demonstrates how to use Easylibpal to apply a specific algorithm to a dataset.
# Linear Regression
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Linear Regression
result = Easylibpal.apply_algorithm('linear_regression', target_column='target')
# Print the result
print(result)
```
# Logistic Regression
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Logistic Regression
result = Easylibpal.apply_algorithm('logistic_regression', target_column='target')
# Print the result
print(result)
```
# Support Vector Machines (SVM)
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply SVM
result = Easylibpal.apply_algorithm('svm', target_column='target')
# Print the result
print(result)
```
# Naive Bayes
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Naive Bayes
result = Easylibpal.apply_algorithm('naive_bayes', target_column='target')
# Print the result
print(result)
```
# K-Nearest Neighbors (K-NN)
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply K-NN
result = Easylibpal.apply_algorithm('knn', target_column='target')
# Print the result
print(result)
```
ABSTRACTION AND ESSENTIAL COMPLEXITY
- Essential Complexity: This refers to the inherent complexity of the problem domain, which cannot be reduced regardless of the programming language or framework used. It includes the logic and algorithm needed to solve the problem. For example, the essential complexity of sorting a list remains the same across different programming languages.
- Accidental Complexity: This is the complexity introduced by the choice of programming language, framework, or libraries. It can be reduced or eliminated through abstraction. For instance, using a high-level API in Python can hide the complexity of lower-level operations, making the code more readable and maintainable.
HOW EASYLIBPAL ABSTRACTS COMPLEXITY
Easylibpal aims to reduce accidental complexity by providing a high-level API that encapsulates the details of each classic AI algorithm. This abstraction allows users to apply these algorithms without needing to understand the underlying mechanisms or the specifics of the algorithm's implementation.
- Simplified Interface: Easylibpal offers a unified interface for applying various algorithms, such as Linear Regression, Logistic Regression, SVM, Naive Bayes, and K-NN. This interface abstracts the complexity of each algorithm, making it easier for users to apply them to their datasets.
- Runtime Fusion: By evaluating sub-expressions and sharing them across multiple terms, Easylibpal can optimize the execution of algorithms. This approach, similar to runtime fusion in abstract algorithms, allows for efficient computation without duplicating work, thereby reducing the computational complexity.
- Focus on Essential Complexity: While Easylibpal abstracts away the accidental complexity; it ensures that the essential complexity of the problem domain remains at the forefront. This means that while the implementation details are hidden, the core logic and algorithmic approach are still accessible and understandable to the user.
To implement Easylibpal, one would need to create a Python class that encapsulates the functionality of each classic AI algorithm. This class would provide methods for loading datasets, preprocessing data, and applying the algorithm with minimal configuration required from the user. The implementation would leverage existing libraries like scikit-learn for the actual algorithmic computations, abstracting away the complexity of these libraries.
Here's a conceptual example of how the Easylibpal class might be structured for applying a Linear Regression algorithm:
```python
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Abstracted implementation of Linear Regression
# This method would internally use scikit-learn or another library
# to perform the actual computation, abstracting the complexity
pass
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
result = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates the concept of Easylibpal by abstracting the complexity of applying a Linear Regression algorithm. The actual implementation would need to include the specifics of loading the dataset, preprocessing it, and applying the algorithm using an underlying library like scikit-learn.
Easylibpal abstracts the complexity of classic AI algorithms by providing a simplified interface that hides the intricacies of each algorithm's implementation. This abstraction allows users to apply these algorithms with minimal configuration and understanding of the underlying mechanisms. Here are examples of specific algorithms that Easylibpal abstracts:
To implement Easylibpal, one would need to create a Python class that encapsulates the functionality of each classic AI algorithm. This class would provide methods for loading datasets, preprocessing data, and applying the algorithm with minimal configuration required from the user. The implementation would leverage existing libraries like scikit-learn for the actual algorithmic computations, abstracting away the complexity of these libraries.
Here's a conceptual example of how the Easylibpal class might be structured for applying a Linear Regression algorithm:
```python
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Abstracted implementation of Linear Regression
# This method would internally use scikit-learn or another library
# to perform the actual computation, abstracting the complexity
pass
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
result = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates the concept of Easylibpal by abstracting the complexity of applying a Linear Regression algorithm. The actual implementation would need to include the specifics of loading the dataset, preprocessing it, and applying the algorithm using an underlying library like scikit-learn.
Easylibpal abstracts the complexity of feature selection for classic AI algorithms by providing a simplified interface that automates the process of selecting the most relevant features for each algorithm. This abstraction is crucial because feature selection is a critical step in machine learning that can significantly impact the performance of a model. Here's how Easylibpal handles feature selection for the mentioned algorithms:
To implement feature selection in Easylibpal, one could use scikit-learn's `SelectKBest` or `RFE` classes for feature selection based on statistical tests or model coefficients. Here's a conceptual example of how feature selection might be integrated into the Easylibpal class for Linear Regression:
```python
from sklearn.feature_selection import SelectKBest, f_regression
from sklearn.linear_model import LinearRegression
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Feature selection using SelectKBest
selector = SelectKBest(score_func=f_regression, k=10)
X_new = selector.fit_transform(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Train Linear Regression model
model = LinearRegression()
model.fit(X_new, self.dataset[target_column])
# Return the trained model
return model
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
model = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates how Easylibpal abstracts the complexity of feature selection for Linear Regression by using scikit-learn's `SelectKBest` to select the top 10 features based on their statistical significance in predicting the target variable. The actual implementation would need to adapt this approach for each algorithm, considering the specific characteristics and requirements of each algorithm.
To implement feature selection in Easylibpal, one could use scikit-learn's `SelectKBest`, `RFE`, or other feature selection classes based on the algorithm's requirements. Here's a conceptual example of how feature selection might be integrated into the Easylibpal class for Logistic Regression using RFE:
```python
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_logistic_regression(self, target_column):
# Feature selection using RFE
model = LogisticRegression()
rfe = RFE(model, n_features_to_select=10)
rfe.fit(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Train Logistic Regression model
model.fit(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Return the trained model
return model
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
model = Easylibpal.apply_logistic_regression(target_column='target')
```
This example demonstrates how Easylibpal abstracts the complexity of feature selection for Logistic Regression by using scikit-learn's `RFE` to select the top 10 features based on their importance in the model. The actual implementation would need to adapt this approach for each algorithm, considering the specific characteristics and requirements of each algorithm.
EASYLIBPAL HANDLES DIFFERENT TYPES OF DATASETS
Easylibpal handles different types of datasets with varying structures by adopting a flexible and adaptable approach to data preprocessing and transformation. This approach is inspired by the principles of tidy data and the need to ensure data is in a consistent, usable format before applying AI algorithms. Here's how Easylibpal addresses the challenges posed by varying dataset structures:
One Type in Multiple Tables
When datasets contain different variables, the same variables with different names, different file formats, or different conventions for missing values, Easylibpal employs a process similar to tidying data. This involves identifying and standardizing the structure of each dataset, ensuring that each variable is consistently named and formatted across datasets. This process might include renaming columns, converting data types, and handling missing values in a uniform manner. For datasets stored in different file formats, Easylibpal would use appropriate libraries (e.g., pandas for CSV, Excel files, and SQL databases) to load and preprocess the data before applying the algorithms.
Multiple Types in One Table
For datasets that involve values collected at multiple levels or on different types of observational units, Easylibpal applies a normalization process. This involves breaking down the dataset into multiple tables, each representing a distinct type of observational unit. For example, if a dataset contains information about songs and their rankings over time, Easylibpal would separate this into two tables: one for song details and another for rankings. This normalization ensures that each fact is expressed in only one place, reducing inconsistencies and making the data more manageable for analysis.
Data Semantics
Easylibpal ensures that the data is organized in a way that aligns with the principles of data semantics, where every value belongs to a variable and an observation. This organization is crucial for the algorithms to interpret the data correctly. Easylibpal might use functions like `pivot_longer` and `pivot_wider` from the tidyverse or equivalent functions in pandas to reshape the data into a long format, where each row represents a single observation and each column represents a single variable. This format is particularly useful for algorithms that require a consistent structure for input data.
Messy Data
Dealing with messy data, which can include inconsistent data types, missing values, and outliers, is a common challenge in data science. Easylibpal addresses this by implementing robust data cleaning and preprocessing steps. This includes handling missing values (e.g., imputation or deletion), converting data types to ensure consistency, and identifying and removing outliers. These steps are crucial for preparing the data in a format that is suitable for the algorithms, ensuring that the algorithms can effectively learn from the data without being hindered by its inconsistencies.
To implement these principles in Python, Easylibpal would leverage libraries like pandas for data manipulation and preprocessing. Here's a conceptual example of how Easylibpal might handle a dataset with multiple types in one table:
```python
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Normalize the dataset by separating it into two tables
song_table = dataset'artist', 'track'.drop_duplicates().reset_index(drop=True)
song_table['song_id'] = range(1, len(song_table) + 1)
ranking_table = dataset'artist', 'track', 'week', 'rank'.drop_duplicates().reset_index(drop=True)
# Now, song_table and ranking_table can be used separately for analysis
```
This example demonstrates how Easylibpal might normalize a dataset with multiple types of observational units into separate tables, ensuring that each type of observational unit is stored in its own table. The actual implementation would need to adapt this approach based on the specific structure and requirements of the dataset being processed.
CLEAN DATA
Easylibpal employs a comprehensive set of data cleaning and preprocessing steps to handle messy data, ensuring that the data is in a suitable format for machine learning algorithms. These steps are crucial for improving the accuracy and reliability of the models, as well as preventing misleading results and conclusions. Here's a detailed look at the specific steps Easylibpal might employ:
1. Remove Irrelevant Data
The first step involves identifying and removing data that is not relevant to the analysis or modeling task at hand. This could include columns or rows that do not contribute to the predictive power of the model or are not necessary for the analysis .
2. Deduplicate Data
Deduplication is the process of removing duplicate entries from the dataset. Duplicates can skew the analysis and lead to incorrect conclusions. Easylibpal would use appropriate methods to identify and remove duplicates, ensuring that each entry in the dataset is unique.
3. Fix Structural Errors
Structural errors in the dataset, such as inconsistent data types, incorrect values, or formatting issues, can significantly impact the performance of machine learning algorithms. Easylibpal would employ data cleaning techniques to correct these errors, ensuring that the data is consistent and correctly formatted.
4. Deal with Missing Data
Handling missing data is a common challenge in data preprocessing. Easylibpal might use techniques such as imputation (filling missing values with statistical estimates like mean, median, or mode) or deletion (removing rows or columns with missing values) to address this issue. The choice of method depends on the nature of the data and the specific requirements of the analysis.
5. Filter Out Data Outliers
Outliers can significantly affect the performance of machine learning models. Easylibpal would use statistical methods to identify and filter out outliers, ensuring that the data is more representative of the population being analyzed.
6. Validate Data
The final step involves validating the cleaned and preprocessed data to ensure its quality and accuracy. This could include checking for consistency, verifying the correctness of the data, and ensuring that the data meets the requirements of the machine learning algorithms. Easylibpal would employ validation techniques to confirm that the data is ready for analysis.
To implement these data cleaning and preprocessing steps in Python, Easylibpal would leverage libraries like pandas and scikit-learn. Here's a conceptual example of how these steps might be integrated into the Easylibpal class:
```python
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def clean_and_preprocess(self):
# Remove irrelevant data
self.dataset = self.dataset.drop(['irrelevant_column'], axis=1)
# Deduplicate data
self.dataset = self.dataset.drop_duplicates()
# Fix structural errors (example: correct data type)
self.dataset['correct_data_type_column'] = self.dataset['correct_data_type_column'].astype(float)
# Deal with missing data (example: imputation)
imputer = SimpleImputer(strategy='mean')
self.dataset['missing_data_column'] = imputer.fit_transform(self.dataset'missing_data_column')
# Filter out data outliers (example: using Z-score)
# This step requires a more detailed implementation based on the specific dataset
# Validate data (example: checking for NaN values)
assert not self.dataset.isnull().values.any(), "Data still contains NaN values"
# Return the cleaned and preprocessed dataset
return self.dataset
# Usage
Easylibpal = Easylibpal(dataset=pd.read_csv('your_dataset.csv'))
cleaned_dataset = Easylibpal.clean_and_preprocess()
```
This example demonstrates a simplified approach to data cleaning and preprocessing within Easylibpal. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
VALUE DATA
Easylibpal determines which data is irrelevant and can be removed through a combination of domain knowledge, data analysis, and automated techniques. The process involves identifying data that does not contribute to the analysis, research, or goals of the project, and removing it to improve the quality, efficiency, and clarity of the data. Here's how Easylibpal might approach this:
Domain Knowledge
Easylibpal leverages domain knowledge to identify data that is not relevant to the specific goals of the analysis or modeling task. This could include data that is out of scope, outdated, duplicated, or erroneous. By understanding the context and objectives of the project, Easylibpal can systematically exclude data that does not add value to the analysis.
Data Analysis
Easylibpal employs data analysis techniques to identify irrelevant data. This involves examining the dataset to understand the relationships between variables, the distribution of data, and the presence of outliers or anomalies. Data that does not have a significant impact on the predictive power of the model or the insights derived from the analysis is considered irrelevant.
Automated Techniques
Easylibpal uses automated tools and methods to remove irrelevant data. This includes filtering techniques to select or exclude certain rows or columns based on criteria or conditions, aggregating data to reduce its complexity, and deduplicating to remove duplicate entries. Tools like Excel, Google Sheets, Tableau, Power BI, OpenRefine, Python, R, Data Linter, Data Cleaner, and Data Wrangler can be employed for these purposes .
Examples of Irrelevant Data
- Personal Identifiable Information (PII): Data such as names, addresses, and phone numbers are irrelevant for most analytical purposes and should be removed to protect privacy and comply with data protection regulations .
- URLs and HTML Tags: These are typically not relevant to the analysis and can be removed to clean up the dataset.
- Boilerplate Text: Excessive blank space or boilerplate text (e.g., in emails) adds noise to the data and can be removed.
- Tracking Codes: These are used for tracking user interactions and do not contribute to the analysis.
To implement these steps in Python, Easylibpal might use pandas for data manipulation and filtering. Here's a conceptual example of how to remove irrelevant data:
```python
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Remove irrelevant columns (example: email addresses)
dataset = dataset.drop(['email_address'], axis=1)
# Remove rows with missing values (example: if a column is required for analysis)
dataset = dataset.dropna(subset=['required_column'])
# Deduplicate data
dataset = dataset.drop_duplicates()
# Return the cleaned dataset
cleaned_dataset = dataset
```
This example demonstrates how Easylibpal might remove irrelevant data from a dataset using Python and pandas. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Detecting Inconsistencies
Easylibpal starts by detecting inconsistencies in the data. This involves identifying discrepancies in data types, missing values, duplicates, and formatting errors. By detecting these inconsistencies, Easylibpal can take targeted actions to address them.
Handling Formatting Errors
Formatting errors, such as inconsistent data types for the same feature, can significantly impact the analysis. Easylibpal uses functions like `astype()` in pandas to convert data types, ensuring uniformity and consistency across the dataset. This step is crucial for preparing the data for analysis, as it ensures that each feature is in the correct format expected by the algorithms.
Handling Missing Values
Missing values are a common issue in datasets. Easylibpal addresses this by consulting with subject matter experts to understand why data might be missing. If the missing data is missing completely at random, Easylibpal might choose to drop it. However, for other cases, Easylibpal might employ imputation techniques to fill in missing values, ensuring that the dataset is complete and ready for analysis.
Handling Duplicates
Duplicate entries can skew the analysis and lead to incorrect conclusions. Easylibpal uses pandas to identify and remove duplicates, ensuring that each entry in the dataset is unique. This step is crucial for maintaining the integrity of the data and ensuring that the analysis is based on distinct observations.
Handling Inconsistent Values
Inconsistent values, such as different representations of the same concept (e.g., "yes" vs. "y" for a binary variable), can also pose challenges. Easylibpal employs data cleaning techniques to standardize these values, ensuring that the data is consistent and can be accurately analyzed.
To implement these steps in Python, Easylibpal would leverage pandas for data manipulation and preprocessing. Here's a conceptual example of how these steps might be integrated into the Easylibpal class:
```python
import pandas as pd
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def clean_and_preprocess(self):
# Detect inconsistencies (example: check data types)
print(self.dataset.dtypes)
# Handle formatting errors (example: convert data types)
self.dataset['date_column'] = pd.to_datetime(self.dataset['date_column'])
# Handle missing values (example: drop rows with missing values)
self.dataset = self.dataset.dropna(subset=['required_column'])
# Handle duplicates (example: drop duplicates)
self.dataset = self.dataset.drop_duplicates()
# Handle inconsistent values (example: standardize values)
self.dataset['binary_column'] = self.dataset['binary_column'].map({'yes': 1, 'no': 0})
# Return the cleaned and preprocessed dataset
return self.dataset
# Usage
Easylibpal = Easylibpal(dataset=pd.read_csv('your_dataset.csv'))
cleaned_dataset = Easylibpal.clean_and_preprocess()
```
This example demonstrates a simplified approach to handling inconsistent or messy data within Easylibpal. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Statistical Imputation
Statistical imputation involves replacing missing values with statistical estimates such as the mean, median, or mode of the available data. This method is straightforward and can be effective for numerical data. For categorical data, mode imputation is commonly used. The choice of imputation method depends on the distribution of the data and the nature of the missing values.
Model-Based Imputation
Model-based imputation uses machine learning models to predict missing values. This approach can be more sophisticated and potentially more accurate than statistical imputation, especially for complex datasets. Techniques like K-Nearest Neighbors (KNN) imputation can be used, where the missing values are replaced with the values of the K nearest neighbors in the feature space.
Using SimpleImputer in scikit-learn
The scikit-learn library provides the `SimpleImputer` class, which supports both statistical and model-based imputation. `SimpleImputer` can be used to replace missing values with the mean, median, or most frequent value (mode) of the column. It also supports more advanced imputation methods like KNN imputation.
To implement these imputation techniques in Python, Easylibpal might use the `SimpleImputer` class from scikit-learn. Here's an example of how to use `SimpleImputer` for statistical imputation:
```python
from sklearn.impute import SimpleImputer
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Initialize SimpleImputer for numerical columns
num_imputer = SimpleImputer(strategy='mean')
# Fit and transform the numerical columns
dataset'numerical_column1', 'numerical_column2' = num_imputer.fit_transform(dataset'numerical_column1', 'numerical_column2')
# Initialize SimpleImputer for categorical columns
cat_imputer = SimpleImputer(strategy='most_frequent')
# Fit and transform the categorical columns
dataset'categorical_column1', 'categorical_column2' = cat_imputer.fit_transform(dataset'categorical_column1', 'categorical_column2')
# The dataset now has missing values imputed
```
This example demonstrates how to use `SimpleImputer` to fill in missing values in both numerical and categorical columns of a dataset. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Model-based imputation techniques, such as Multiple Imputation by Chained Equations (MICE), offer powerful ways to handle missing data by using statistical models to predict missing values. However, these techniques come with their own set of limitations and potential drawbacks:
1. Complexity and Computational Cost
Model-based imputation methods can be computationally intensive, especially for large datasets or complex models. This can lead to longer processing times and increased computational resources required for imputation.
2. Overfitting and Convergence Issues
These methods are prone to overfitting, where the imputation model captures noise in the data rather than the underlying pattern. Overfitting can lead to imputed values that are too closely aligned with the observed data, potentially introducing bias into the analysis. Additionally, convergence issues may arise, where the imputation process does not settle on a stable solution.
3. Assumptions About Missing Data
Model-based imputation techniques often assume that the data is missing at random (MAR), which means that the probability of a value being missing is not related to the values of other variables. However, this assumption may not hold true in all cases, leading to biased imputations if the data is missing not at random (MNAR).
4. Need for Suitable Regression Models
For each variable with missing values, a suitable regression model must be chosen. Selecting the wrong model can lead to inaccurate imputations. The choice of model depends on the nature of the data and the relationship between the variable with missing values and other variables.
5. Combining Imputed Datasets
After imputing missing values, there is a challenge in combining the multiple imputed datasets to produce a single, final dataset. This requires careful consideration of how to aggregate the imputed values and can introduce additional complexity and uncertainty into the analysis.
6. Lack of Transparency
The process of model-based imputation can be less transparent than simpler imputation methods, such as mean or median imputation. This can make it harder to justify the imputation process, especially in contexts where the reasons for missing data are important, such as in healthcare research.
Despite these limitations, model-based imputation techniques can be highly effective for handling missing data in datasets where a amusingness is MAR and where the relationships between variables are complex. Careful consideration of the assumptions, the choice of models, and the methods for combining imputed datasets are crucial to mitigate these drawbacks and ensure the validity of the imputation process.
USING EASYLIBPAL FOR AI ALGORITHM INTEGRATION OFFERS SEVERAL SIGNIFICANT BENEFITS, PARTICULARLY IN ENHANCING EVERYDAY LIFE AND REVOLUTIONIZING VARIOUS SECTORS. HERE'S A DETAILED LOOK AT THE ADVANTAGES:
1. Enhanced Communication: AI, through Easylibpal, can significantly improve communication by categorizing messages, prioritizing inboxes, and providing instant customer support through chatbots. This ensures that critical information is not missed and that customer queries are resolved promptly.
2. Creative Endeavors: Beyond mundane tasks, AI can also contribute to creative endeavors. For instance, photo editing applications can use AI algorithms to enhance images, suggesting edits that align with aesthetic preferences. Music composition tools can generate melodies based on user input, inspiring musicians and amateurs alike to explore new artistic horizons. These innovations empower individuals to express themselves creatively with AI as a collaborative partner.
3. Daily Life Enhancement: AI, integrated through Easylibpal, has the potential to enhance daily life exponentially. Smart homes equipped with AI-driven systems can adjust lighting, temperature, and security settings according to user preferences. Autonomous vehicles promise safer and more efficient commuting experiences. Predictive analytics can optimize supply chains, reducing waste and ensuring goods reach users when needed.
4. Paradigm Shift in Technology Interaction: The integration of AI into our daily lives is not just a trend; it's a paradigm shift that's redefining how we interact with technology. By streamlining routine tasks, personalizing experiences, revolutionizing healthcare, enhancing communication, and fueling creativity, AI is opening doors to a more convenient, efficient, and tailored existence.
5. Responsible Benefit Harnessing: As we embrace AI's transformational power, it's essential to approach its integration with a sense of responsibility, ensuring that its benefits are harnessed for the betterment of society as a whole. This approach aligns with the ethical considerations of using AI, emphasizing the importance of using AI in a way that benefits all stakeholders.
In summary, Easylibpal facilitates the integration and use of AI algorithms in a manner that is accessible and beneficial across various domains, from enhancing communication and creative endeavors to revolutionizing daily life and promoting a paradigm shift in technology interaction. This integration not only streamlines the application of AI but also ensures that its benefits are harnessed responsibly for the betterment of society.
USING EASYLIBPAL OVER TRADITIONAL AI LIBRARIES OFFERS SEVERAL BENEFITS, PARTICULARLY IN TERMS OF EASE OF USE, EFFICIENCY, AND THE ABILITY TO APPLY AI ALGORITHMS WITH MINIMAL CONFIGURATION. HERE ARE THE KEY ADVANTAGES:
- Simplified Integration: Easylibpal abstracts the complexity of traditional AI libraries, making it easier for users to integrate classic AI algorithms into their projects. This simplification reduces the learning curve and allows developers and data scientists to focus on their core tasks without getting bogged down by the intricacies of AI implementation.
- User-Friendly Interface: By providing a unified platform for various AI algorithms, Easylibpal offers a user-friendly interface that streamlines the process of selecting and applying algorithms. This interface is designed to be intuitive and accessible, enabling users to experiment with different algorithms with minimal effort.
- Enhanced Productivity: The ability to effortlessly instantiate algorithms, fit models with training data, and make predictions with minimal configuration significantly enhances productivity. This efficiency allows for rapid prototyping and deployment of AI solutions, enabling users to bring their ideas to life more quickly.
- Democratization of AI: Easylibpal democratizes access to classic AI algorithms, making them accessible to a wider range of users, including those with limited programming experience. This democratization empowers users to leverage AI in various domains, fostering innovation and creativity.
- Automation of Repetitive Tasks: By automating the process of applying AI algorithms, Easylibpal helps users save time on repetitive tasks, allowing them to focus on more complex and creative aspects of their projects. This automation is particularly beneficial for users who may not have extensive experience with AI but still wish to incorporate AI capabilities into their work.
- Personalized Learning and Discovery: Easylibpal can be used to enhance personalized learning experiences and discovery mechanisms, similar to the benefits seen in academic libraries. By analyzing user behaviors and preferences, Easylibpal can tailor recommendations and resource suggestions to individual needs, fostering a more engaging and relevant learning journey.
- Data Management and Analysis: Easylibpal aids in managing large datasets efficiently and deriving meaningful insights from data. This capability is crucial in today's data-driven world, where the ability to analyze and interpret large volumes of data can significantly impact research outcomes and decision-making processes.
In summary, Easylibpal offers a simplified, user-friendly approach to applying classic AI algorithms, enhancing productivity, democratizing access to AI, and automating repetitive tasks. These benefits make Easylibpal a valuable tool for developers, data scientists, and users looking to leverage AI in their projects without the complexities associated with traditional AI libraries.
2 notes
·
View notes
Photo
VIOLET CRAZY Jcink Skin - $60 CAD
VIOLET CRAZY is a fully responsive, mobile-friendly Jcink skin. I’ve made it as user-friendly as possible with easy-to-edit variables and cues within the HTML which are also in the installation guide. Template Set #1 and Freestyle Profile Templates are fully functional with this skin.
Please read my terms of service before purchasing: https://hexxincodes.tumblr.com/post/721896465243537408/terms-conditions Purchase on my kofi: https://ko-fi.com/s/fe74d1a98b
DETAILS -
All colors, fonts, and images set as variables for easy editing
Dark/light toggle
Full HTML templates
Isotope member list
Guidebook with 6 tabs set
Skin changes colors according to member group (10 set up)
Profile app with room for unlimited fields
Automatic tracker in profiles
Forums change accents w/ last poster
Full installation guide
UPON PURCHASE -
Full xml file
HTML templates xml file
Profile fields json
Installation guide pdf
Guidebook txt file
CREDITS - Isotope memberlist script is by Essi, the dark/light toggle script was created by Yuno, #CODE script is by Nicole/Thunderstruck, icons are from Phosphor Icons, automatic tracker by FizzyElf.
#hexxincodes#toggle#responsive#multi sale#skins#templates#skin and templates#price reflects only skin#templates available for additional purchase#price: 51-100
3 notes
·
View notes
Text
Convert JSON To CSS Variables With JavaScript
A small JSON to CSS converter that allows you to define design tokens like colors, fonts, and spacing in JSON and convert them into CSS for use in your stylesheets. It bridges the gap between dynamic data structures and styling and is useful in cases where you need to theme a website dynamically or manage styles in a more structured and maintainable way. How to use it: 1. Include the main script…
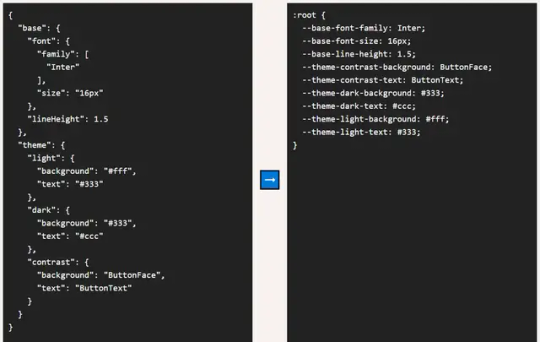
View On WordPress
2 notes
·
View notes